
Artificial Intelligence is now widely recognized as the biggest disruptor in marketing since the internet. OpenAI’s release of GPT-3 five years ago this week (in June 2020) marked the advent of the Large Language Model (LLM) era—the moment it became clear that machines are finally starting to understand us. To teams like ours, the emergent behaviors of these new transformer models, however imperfect, represented something fundamentally different, new, and worthy of the word "intelligent.”

Two more years of product work by the frontier model teams eventually made these models accessible to non-specialists. The release of ChatGPT in November 2022 then launched the industry into a new hype cycle, as users could easily see the value of what became known as generative AI.
This gold rush has led to a wide range of claims about what AI can or will do, from the sober-minded to the far-fetched. To ensure they’re making good decisions, marketers and other business leaders need to distinguish which is which.
Some claims represent genuinely fertile areas of technical and product development: agentic AI, for example, is raising the bar on AI automation and problem-solving capabilities. Others represent a lot of heat but little light, pitting empty prognostications against each other over ill-defined concepts like “AGI” or the “singularity.” So where does “synthetic sample” fall?
The potential of synthetic sample
Following the release of the groundbreaking paper Predicting Results of Social Science Experiments Using Large Language Models, by Swayable research alumnus and MIT cognitive science PhD Luke Hewitt and his co-authors, an intriguing possibility was raised: could survey responses in consumer research be replaced by LLM completions? And if so, in what circumstances?
The Hewitt et al paper demonstrated for the first time that for a range of social science survey experiments, LLM responses were able to predict the outcomes from human subjects. This was a surprising and profound result, raising important follow-up questions, such as why this is the case, and what the bounds are around where predictions make sense vs. where they don’t.
While this research continues—at Swayable and in the broader research community—some commentators have raced ahead to suggest we might one day eliminate the consumer entirely from some consumer research, perhaps even today. Since we have been asked about this increasingly regularly, we figured it would be helpful to share our perspective.
What synthetic sample can do
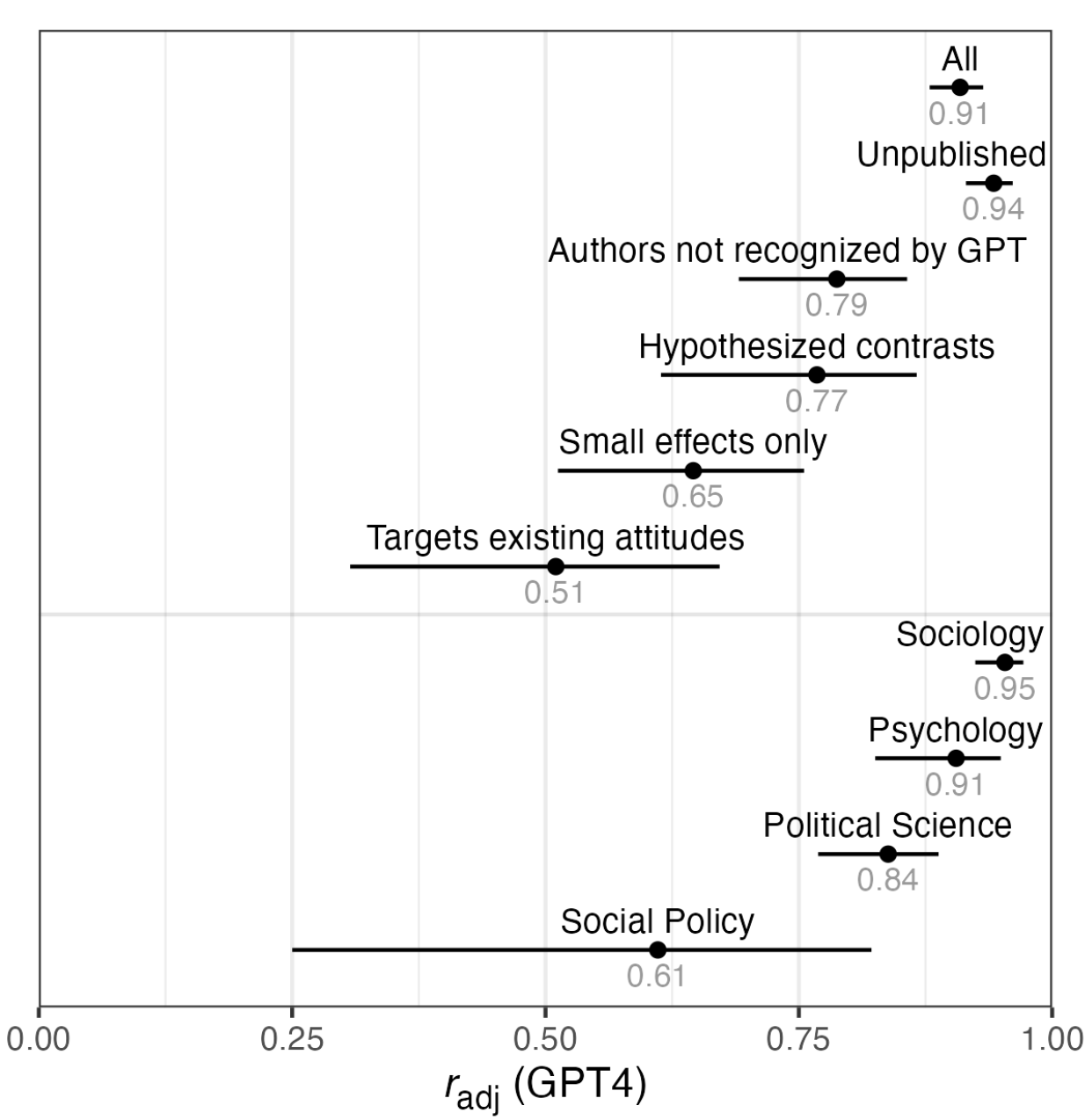
The Hewitt et al paper analyzed 70 survey experiment-based studies in fields such as psychology, political science, and public health. These studies addressed topics like reducing prejudicial attitudes, political partisanship, and misinformation.
In several domains (sociology, psychology, and political science), the outputs of LLMs were consistent enough with human responses that experiments could be simulated with a surprisingly high level of predictive accuracy. This is an extraordinarily interesting finding. It points to the self-organization of implicit logic within LLMs during their pre-training that somehow maps faithfully not just to the opinions of real humans, but to the way those opinions can be changed by giving them new information. Five years after the introduction of GPT-3, we continue to be in awe at the knowledge this type of neural network successfully acquires, often implicit and unnoticed.
For other experiments—sometimes involving more subtle, changing, or context-dependent effects—predictiveness was lower (see below). It may be that more fundamental, basic human reactions (psychology, sociology) are captured within models successfully, while reactions that depend more on present-day or outside-world experiences are not. Our takeaway has been that LLMs successfully encode the implicit logic of some kinds of human responses to stimulus, an extraordinarily interesting finding—but that this depends substantially on the context.
Subsequent research by Stanford computer science PhD student Joon Sung Park (coauthored by other Swayable research partners, as well as team members from Google DeepMind), showed that individual-level behavior can be realistically modeled by constructing LLM-based agents when given detailed interview transcripts from real people. These transcripts included personal histories, experiences, and viewpoints. When included in the model context, the agents produced responses aligned with the human interviewees across a range of social and public policy topics (e.g. views on government spending).
Our takeaway is that the LLMs appear to channel the thinking and attitudes of interview subjects successfully on these societal questions, given the context cues of their words and other viewpoints.
What synthetic sample cannot do
While LLM agent-based approaches offer surprising predictiveness of human responses on these kinds of social policy topics, right now there is no clear evidence about whether, or how, this might extend to marketing. Our expectation is that if an LLM is given knowledge of somebody’s demographics, experiences, and attitudes, their answers to questions like “Do you think courts deal too harshly with criminals?” is likely to be more predictable than the precise relative impact of showing them specific advertising messaging—such as the benefits of switching to T-Mobile.
That’s because marketing choices involve subtle interplay between rapidly evolving consumer tastes, product experiences, and the social, physical, and market environment of the consumer. While it’s not unimaginable that LLM training corpora may contain distillable knowledge that could give them predictive value on this, it will need to be demonstrated by teams with rigorously established ground truth on how the ads do in fact impact consumers’ beliefs. Otherwise, results will just be garbage-in, garbage-out: a problem that cannot be solved by any amount of model complexity.
In our view, optimism is reasonable and experimentation is important—but caution is necessary. It's premature for marketing teams to attempt to implement these nascent research concepts to drive important marketing decisions today. We expect brainstorming and creative ideation to be the earliest sensible applications of synthetic sample ideas in real marketing contexts, since value can be derived whether or not the outputs reliably predict anything.
AI predictions must be continuously grounded in real human measurement
For synthetic sample strategies to offer meaningful insight into the impact of marketing, several basic questions have to be answered first. This starts with whether, in what contexts, and how in-silico simulations can be demonstrated as predictive of real-world marketing experiments. That is not something that can just be assumed, asserted, or established by reference to the sophistication or complexity of models.
Synthetic sample also is not just one defined concept. This is a new phrase representing a range of possible ideas on how any of a million AI models might be combined with workflows, prompts, analysis, and fine-tuning to supply answers that may (or may not) predict human responses.
Ultimately the only way any of these approaches can be established as predictive, and hence of any value, is by starting with the largest possible dataset of high-powered, rigorous experiments, ideally over multiple years, so they can be compared properly with the simulations. No short-cuts are possible: without ground truth, “prediction” is just “making stuff up” with a machine.
There are many ways to get these comparisons wrong, so exposing the analysis transparently to scrutiny by other disinterested experts is critical for the comparisons to carry any dispositive weight. Business leaders need to ask a lot of questions, and skepticism is warranted any time black-box “proprietary” approaches are claimed to be “highly predictive” if they cannot be scrutinized adequately.
Swayable is in the fortunate position of having the largest dataset in existence of high-powered randomized controlled trial (RCT) survey experiment results, on both commercial marketing and social impact topics, spanning every industry vertical and every region of the world. We recognize the importance of doing this work and are actively collaborating with our research partners to take the thinking and ideas here forward.
While we do not expect that humans can ever be replaced in consumer marketing research, AI is unlocking enormous efficiencies in how the research is done, and large increases in the power of measurements and speed of extracting usable insights. As practitioners are discovering across a range of fields, the magic comes not from replacing humans, but using AI as leverage.